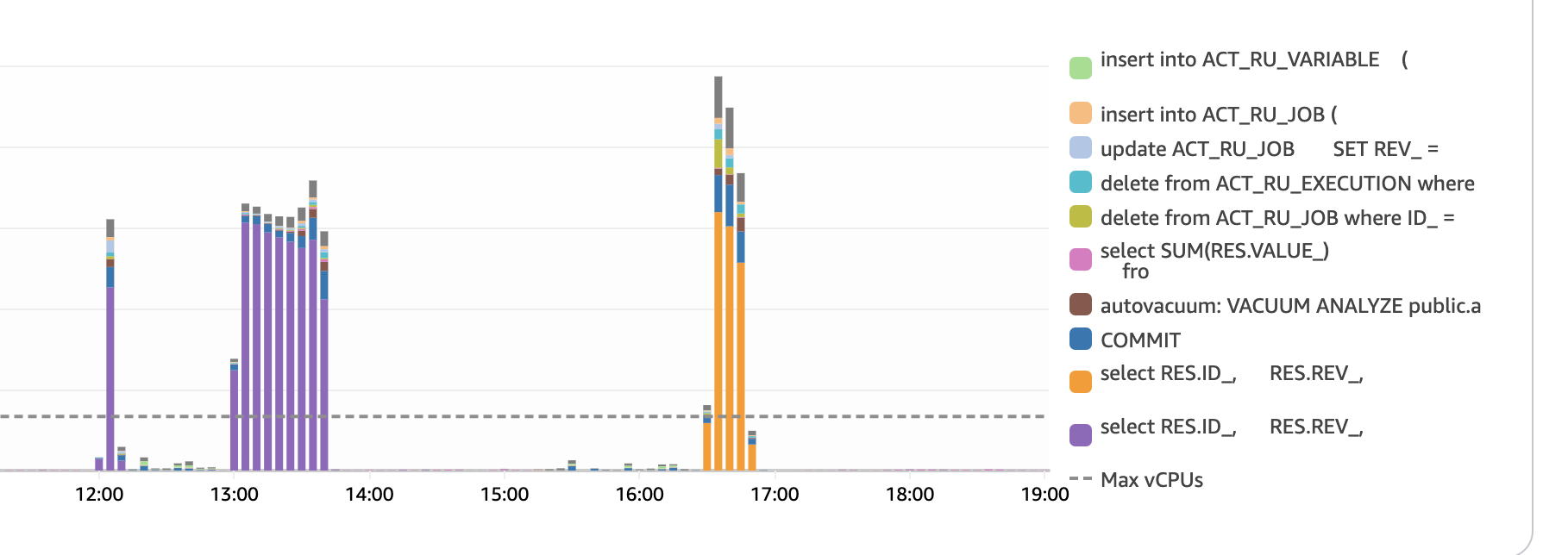
Saturday my test environment was a mess and today i executed it in a better way.
We can really see the improvement of this setting here…
100k process / 300k jobs / 10 pods
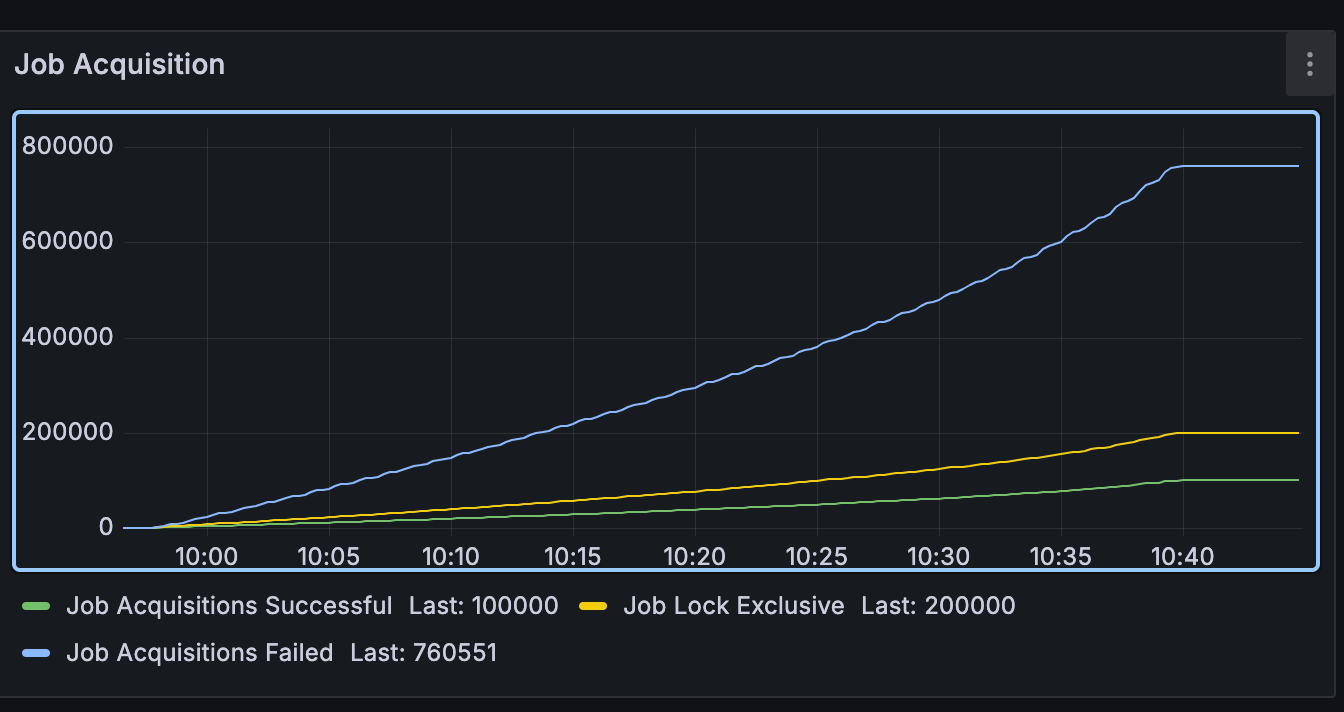
Default implementation:
40minutes total and 760k job acquisition failed
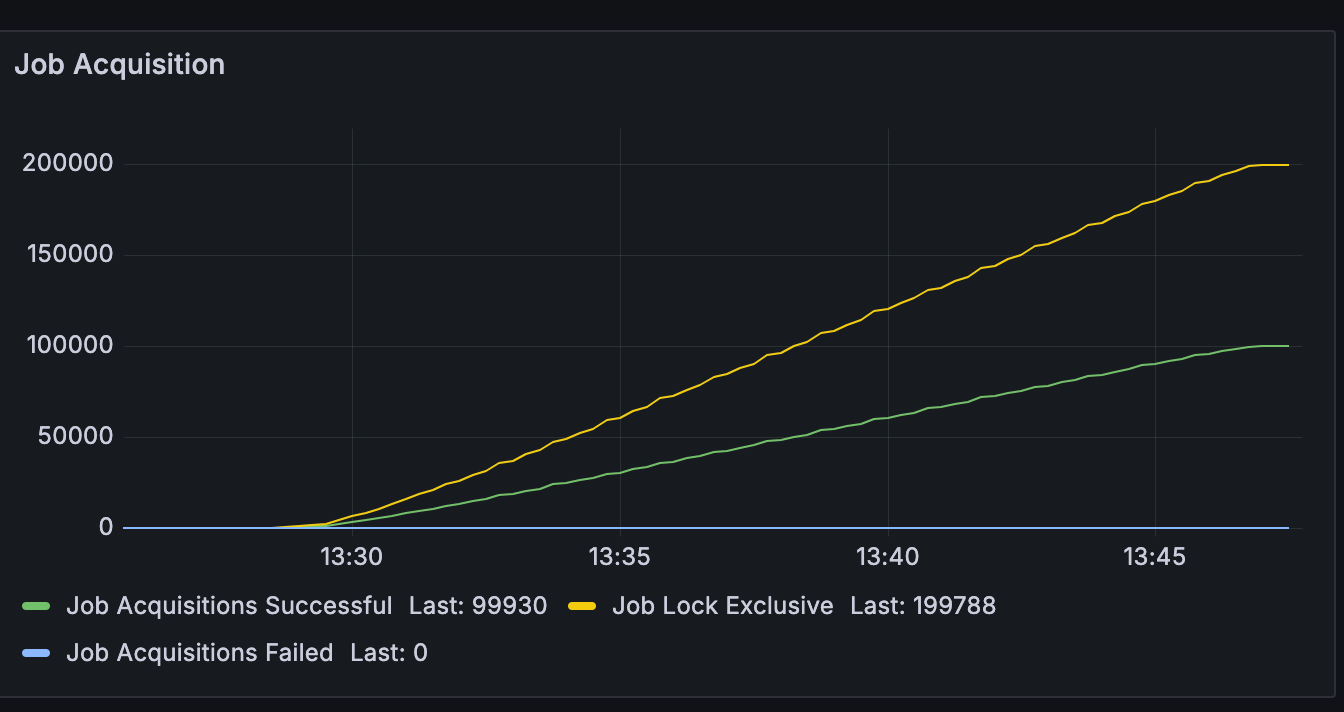
Query updated with FOR UPDATE SKIP LOCK:
16minutes total and ZERO job acquisition faiiled
Finally achived to use 95-100% of my database cpu in a good way. In the default implementation i was capped at 30% cpu, stuck in job acquiisition fails.
Just to show some data
RDS waits:
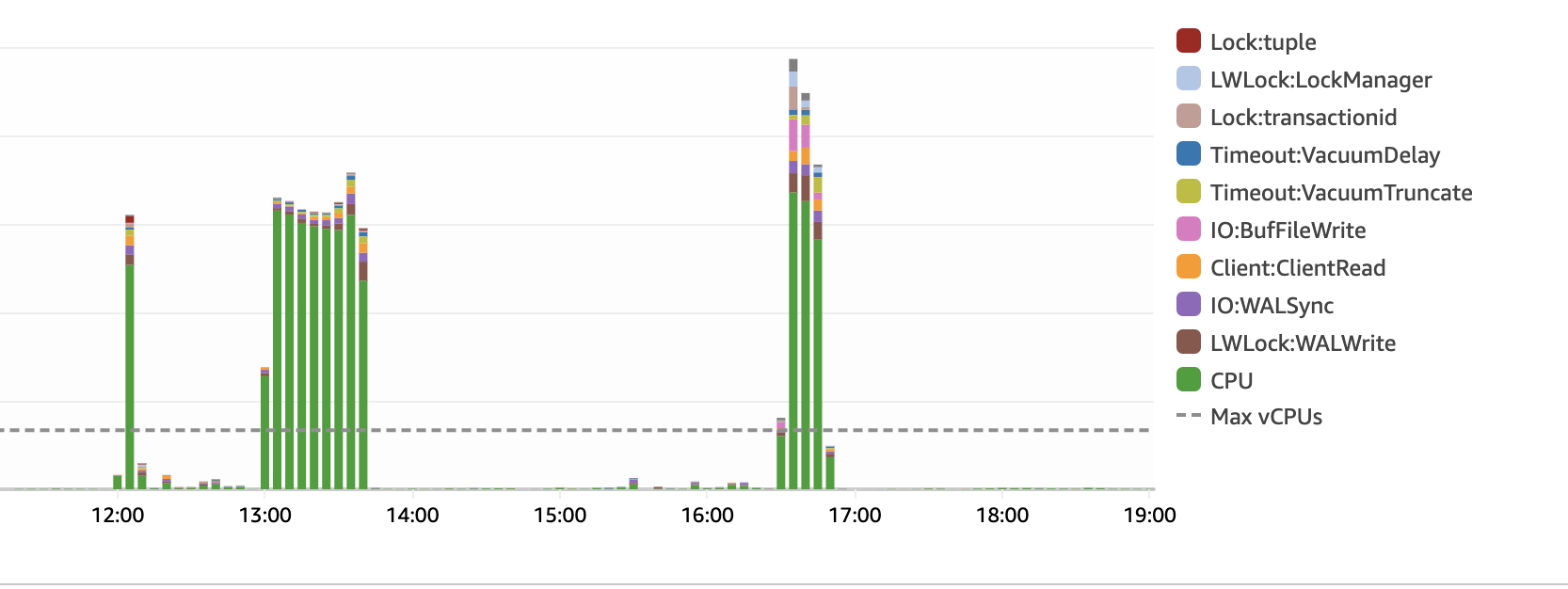
here you can see that there was almost no job execution on the first test, and much more job select/acquisition, while on the second test it was almost all about job inserts.