You are right, patching the engine is not possible for most people Overriding it on the classpath could work, but it might be pretty instable and break with every patch version update.
If you want to try it, I added FOR UPDATE SKIP LOCKED as a new line after the ${limitAfter} in line 230.
@jradesenv can you try this and see if and how this affects your test scenario? Would be really interesting to see if you can reproduce the performance improvements.
I read the documentation about the SKIP LOCKED SQL command and according to the docs it‘s exactly made for this use case.
It‘s of course a hack, you need to copy and patch the file from the exact matching C7 version you‘re using
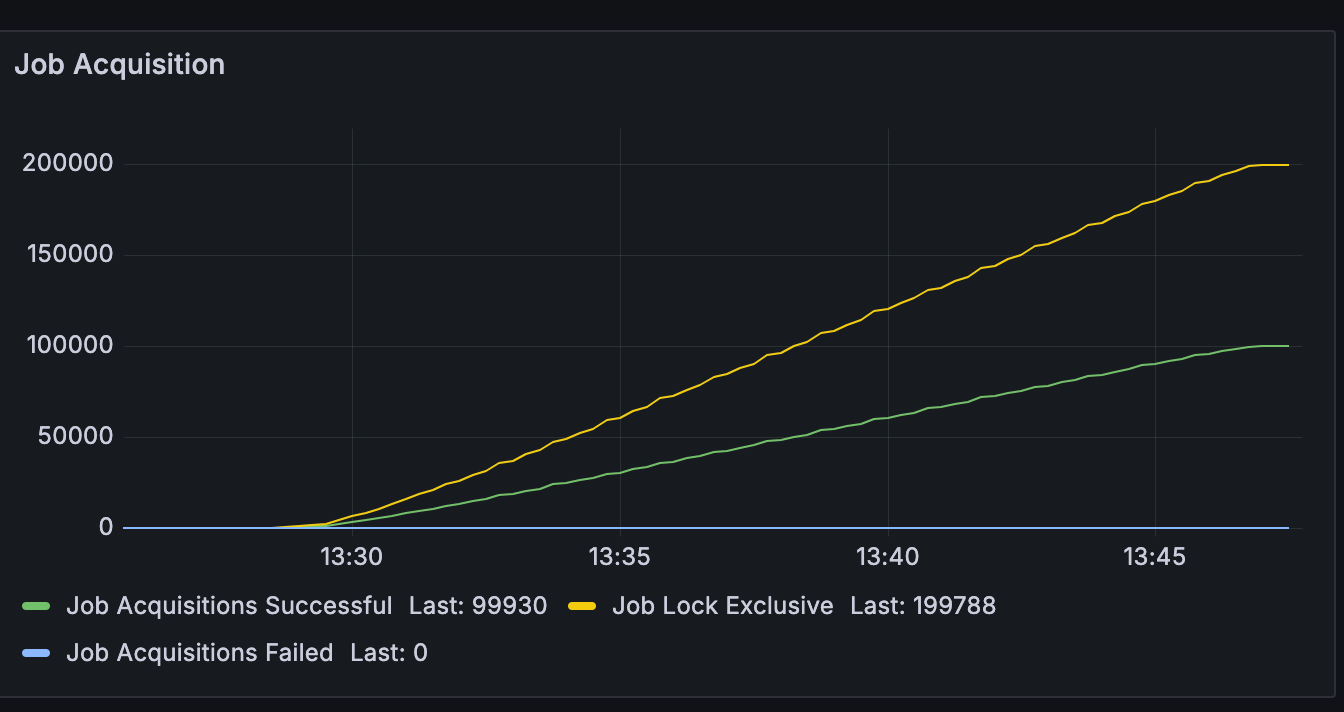
Yeah, tried overriding the file on my resources and it worked! will executed the tests again with the FOR UPDATE SKIP LOCKED and come back here to show results
job executor with pagination + replacing query with FOR UPDATE SKIP LOCKED
I can still see some improvement on jobs per minute with these 2 changes together
job executor default and WITHOUT the addition of FOR UPDATE SKIP LOCKED on the query:
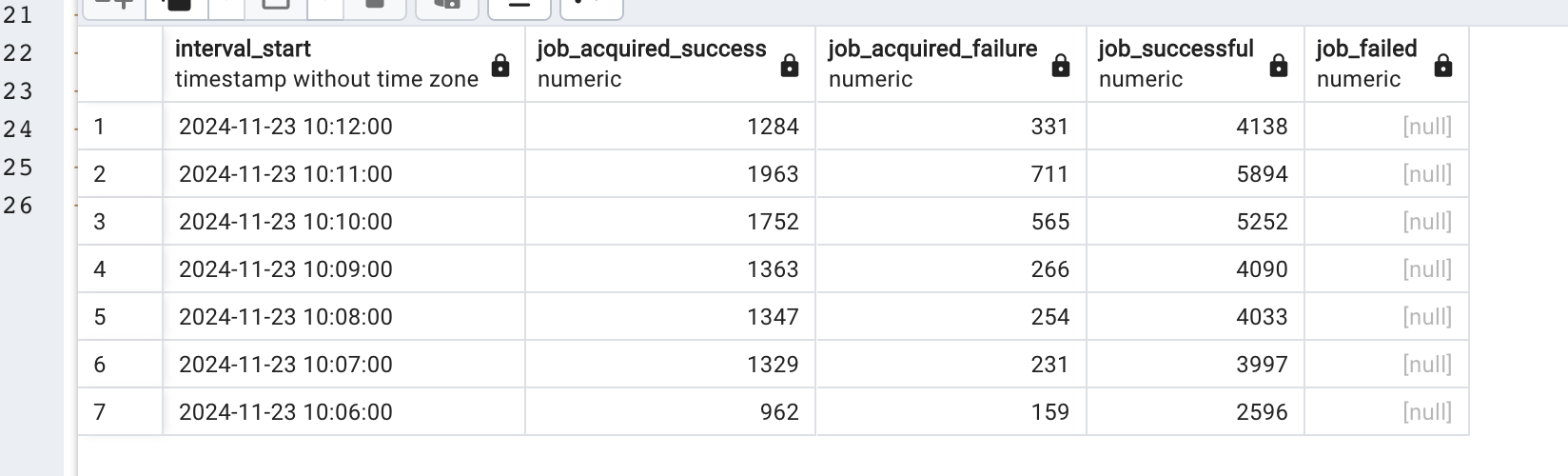
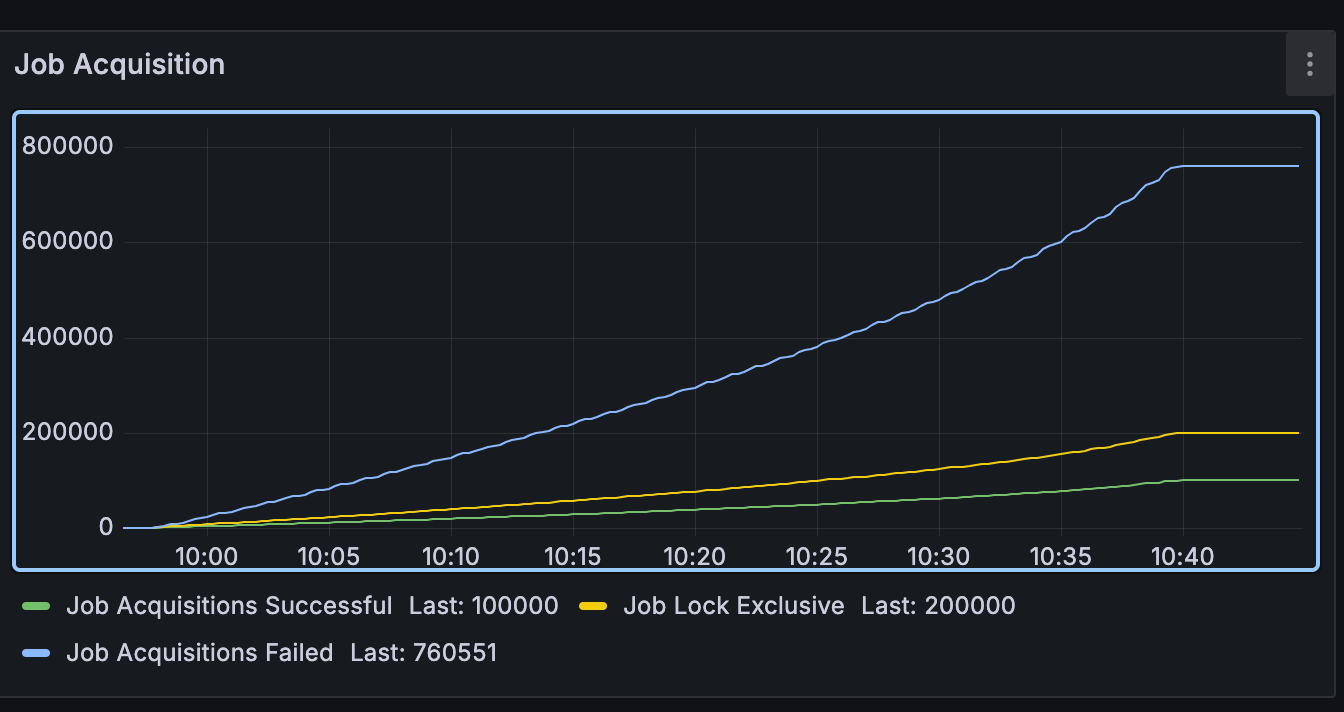
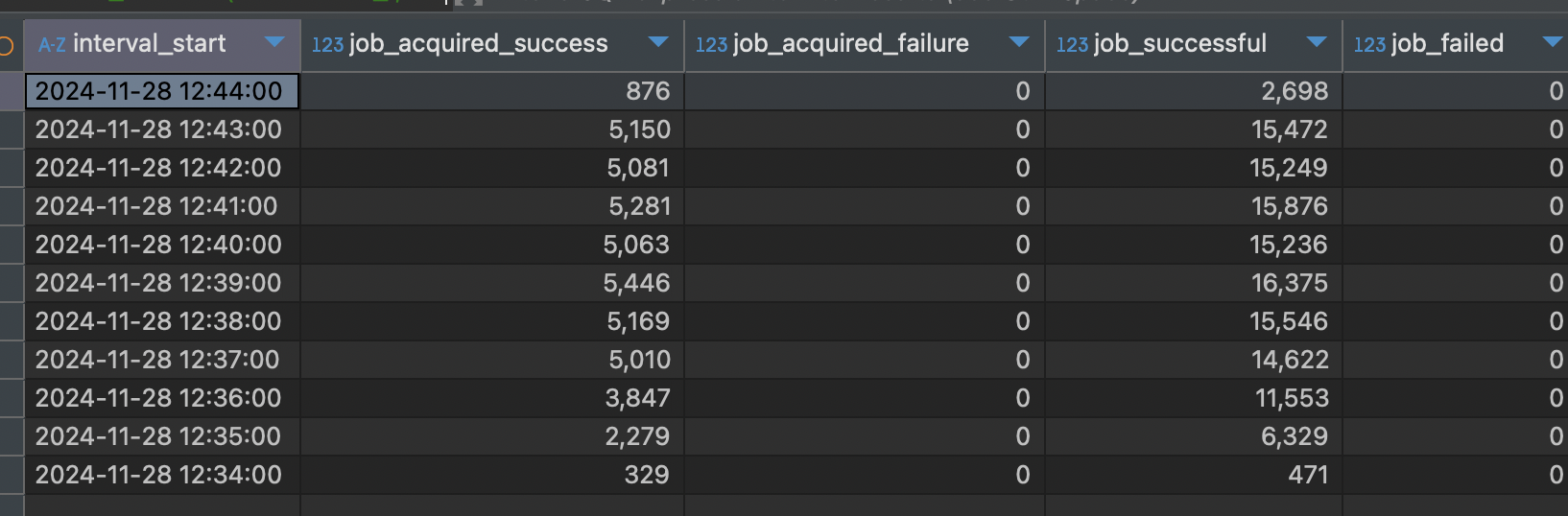
the job acquisiition failure happens as expected but i wasnt expecting it to have better performance than with FOR UPDATE…
job executor with pagination and WITHOUT the addition of FOR UPDATE SKIP LOCKED on the query:
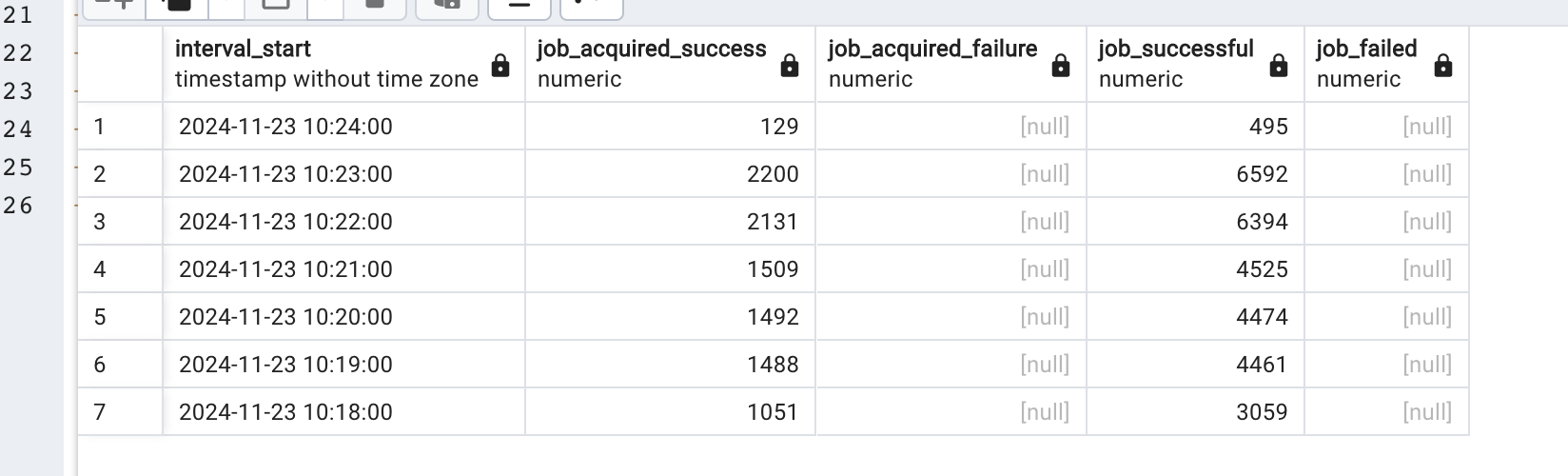
By applying paging/offset I also managed not to have job acquisition failure, and it still appears to be the best performance, but perhaps in a larger test with 100k instances the use of skip locked would avoid overhead in the database by avoiding unnecessary updates that would generate failure.
Thanks for doing those comparisons! I’m not sure if I read your summary-images right, where can I see the execution time? I understood that adding FOR UPDATE SKIP LOCKED reduces the acquisition failures, but decreases performance in general?
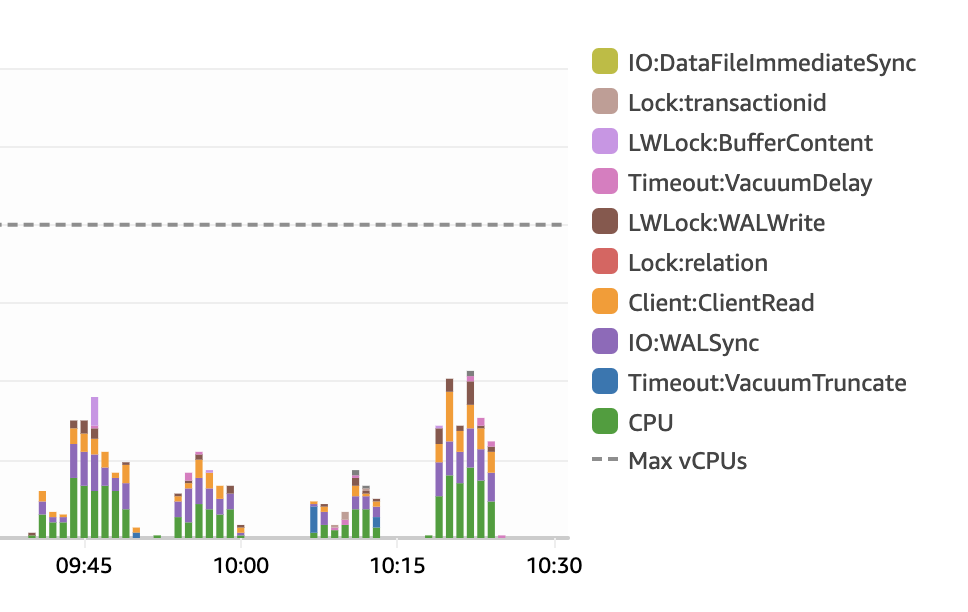
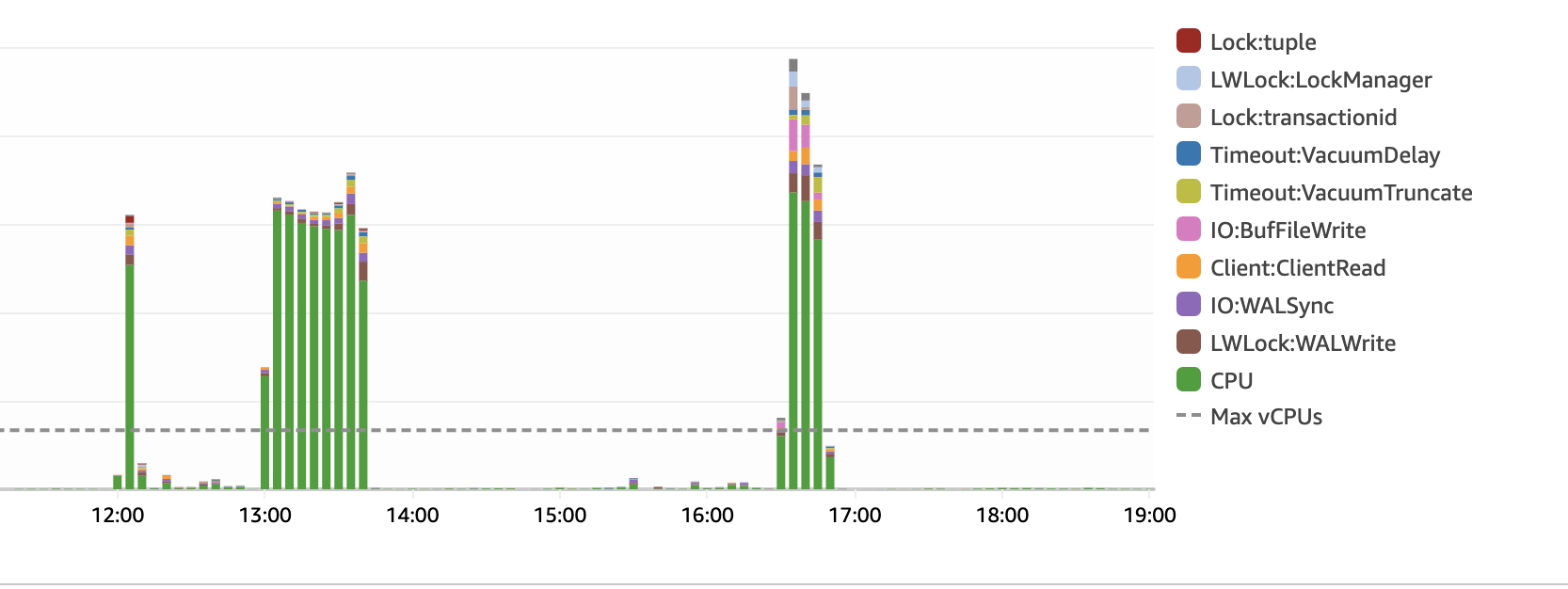
Finally achived to use 95-100% of my database cpu in a good way. In the default implementation i was capped at 30% cpu, stuck in job acquiisition fails.
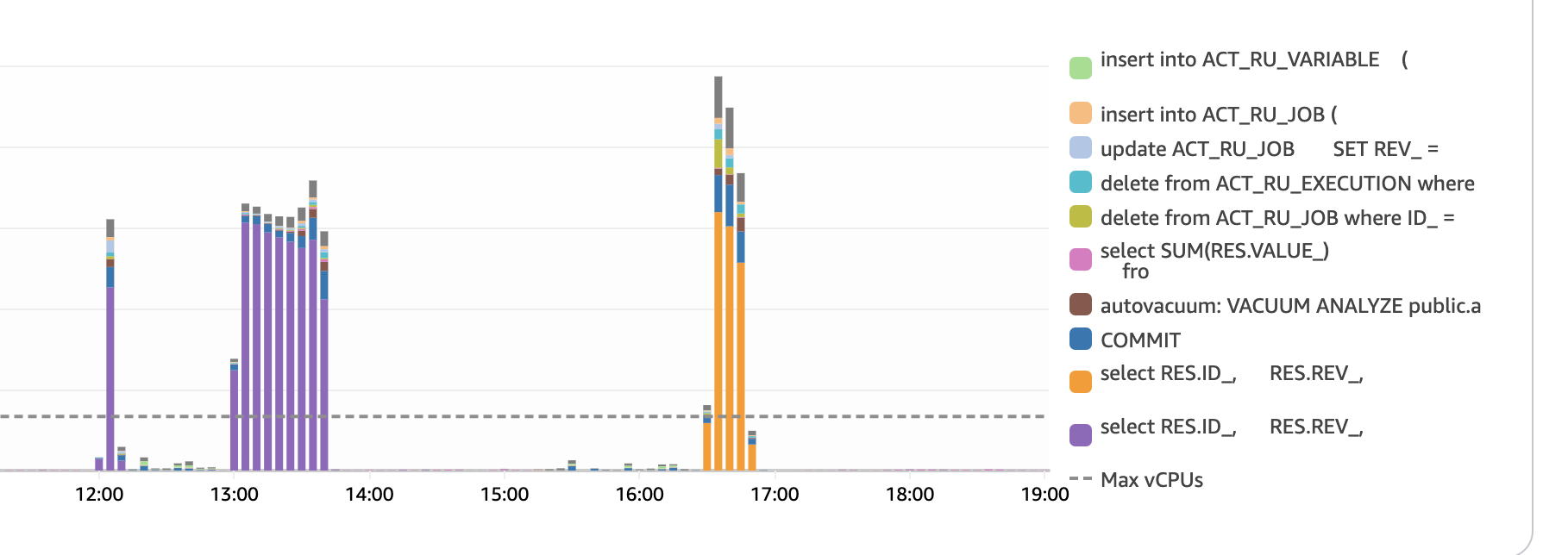
here you can see that there was almost no job execution on the first test, and much more job select/acquisition, while on the second test it was almost all about job inserts.
Thanks for sharing these numbers again! So the “16minutes total and ZERO job acquisition faiiled” is just the FOR UPDATE SKIP LOCK without your custom paging logic, right? That behaves even better than I would have hoped for
I think we could add this as an option to the engine:
Create a new property in the engine configuration (+ Spring Boot + Quarkus), opt in
Allow users to enable this locking mechanism on the job executor
Yep! I’ll will try it plus my custom paging to see if it is still relevant.
But the idea of creating a property to enable this behavior seems a great advance as we dont expect users to override those mybatis xml too often
Im still curious to test it against Mysql too, as i have many projects on this too. Will post the results here when it gets done.
I decided to use only the updated query instead of my paging solution, but i still used the logic that set a single index for each one of my containers to configure a different priority range for the job executor.
This way i have 15 pods total with no concurrency problems (with the FOR UPDATE SKIP LOCKED) and put two of them to work on low priority jobs only (jobPriorityRangeMax(90)). This way all my priority tasks are set from 91 to 100 and the others let as zero.
Yesterday i tested for the first time my 500k+ scenario.
It took 35min to start all the instances (full logic taking objects from my mongodb to process engine and updating its status).
Then restarted the containers with job executor enabled and it took 1:30 to conclude all the 500k+ process instances (which is a complex process with 3 subprocess, parallel gateways for send and receive messages with async before/after)
So, im happy with this throughput and it will work
Just passed by to say thanks for all the sharing we had here and to say that i will keep passing by to discuss new challenges with you all
@jradesenv I’m really happy to hear this! The approach with different priority ranges sounds sensible. Also thanks for testing this with MySQL, also!
I’m currently preparing a pull request which adds an engine config property which allows users to enable FOR UPDATE SKIP LOCKED in the engine itself as an experimental feature for Operaton. If this works and if we get some positive feedback, I think I’ll offer this as a contribution to Camunda, too, in the spirit of OSS
Also, I think I will write a blog post about this on our companies blog, would it be fine for you if I used the numbers you provided here and mention you? If not, that’s totally fine, I think I can recreate those experiments
Just a small update: Implementing this in the engine is not that easy.
After digging into the job executor deeper with @kthoms today, I am a little surprised that it worked that well for you. Currently Camunda is not setting any row level locks in the database, but sets a logical lock. The FOR UPDATE SKIP LOCKED clause obviously does not know about those locks, but obtains its own physical row lock. As long as this is active, other job executor instances will not retrieve this row.
By default, the Job Executor queries all rows, and then sets the logical log in the same transaction. My assumption is, that in the delta between “selecting” and “setting the lock”, other job executors can retrieve this row also, and then try to set the lock, too, which can fail. Due to the additional physical lock, we have prevented this from happening.
So the new row-level physical lock does not lock the job in the database for the whole processing time, but locks it so the logical lock can be safely written.
Everything written here is a hypothesis yet to be proven, I just wanted to give you an update
Hmm, I don’t know if I managed to understand the “problem” with this, because it’s exactly what I expected to happen. By default, camunda has this concurrency problem where several containers are making the same query, getting the same jobs, and the first one manages to set the lock owner and increase the rev_ while the others will get the job acquisition failed because it no longer finds this row with the same rev_ (updated rows zero).
FOR UPDATE then warns the database that this line must remain locked at the db level until the same transaction makes the update, while SKIP LOCKED is precisely to skip these already locked lines. Perhaps the transaction level READ COMMITED will then help eliminate the rest of the competition that may still occur.
Even if there were some job acquisition failing, I understand that it would be minimal, a matter of miliseconds of concurrency, and then it is much better than the standard (where 100k jobs generated 740k failures with 10 containers), and then the logical lock that is done via update still maintains security using rev_ to avoid the minimum competition that may occur.
You’re right with that, I rewrote my post several times and in the end it was confusing.
The tricky thing is testing. We are now adding row level locking for the first time, until now the whole “locking” concept in the engine is entirely logical locks, so we need to make sure that it plays well with all the other configurations. That definitely got lost in my edits, sorry for the confusion