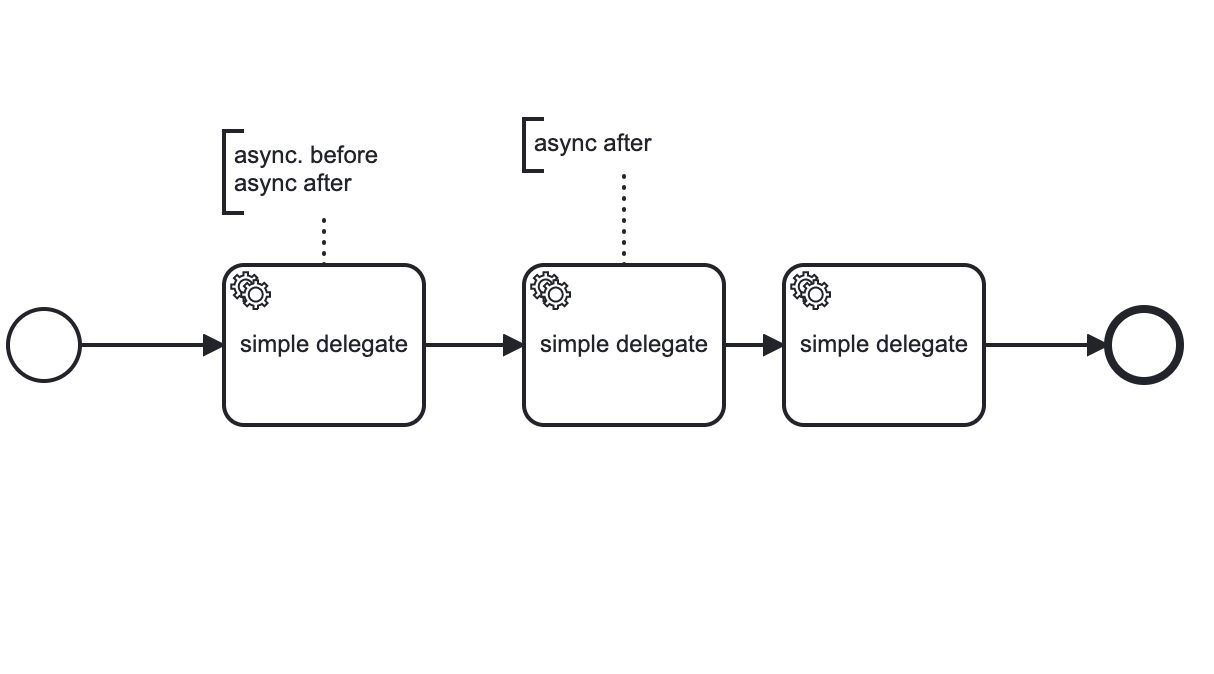
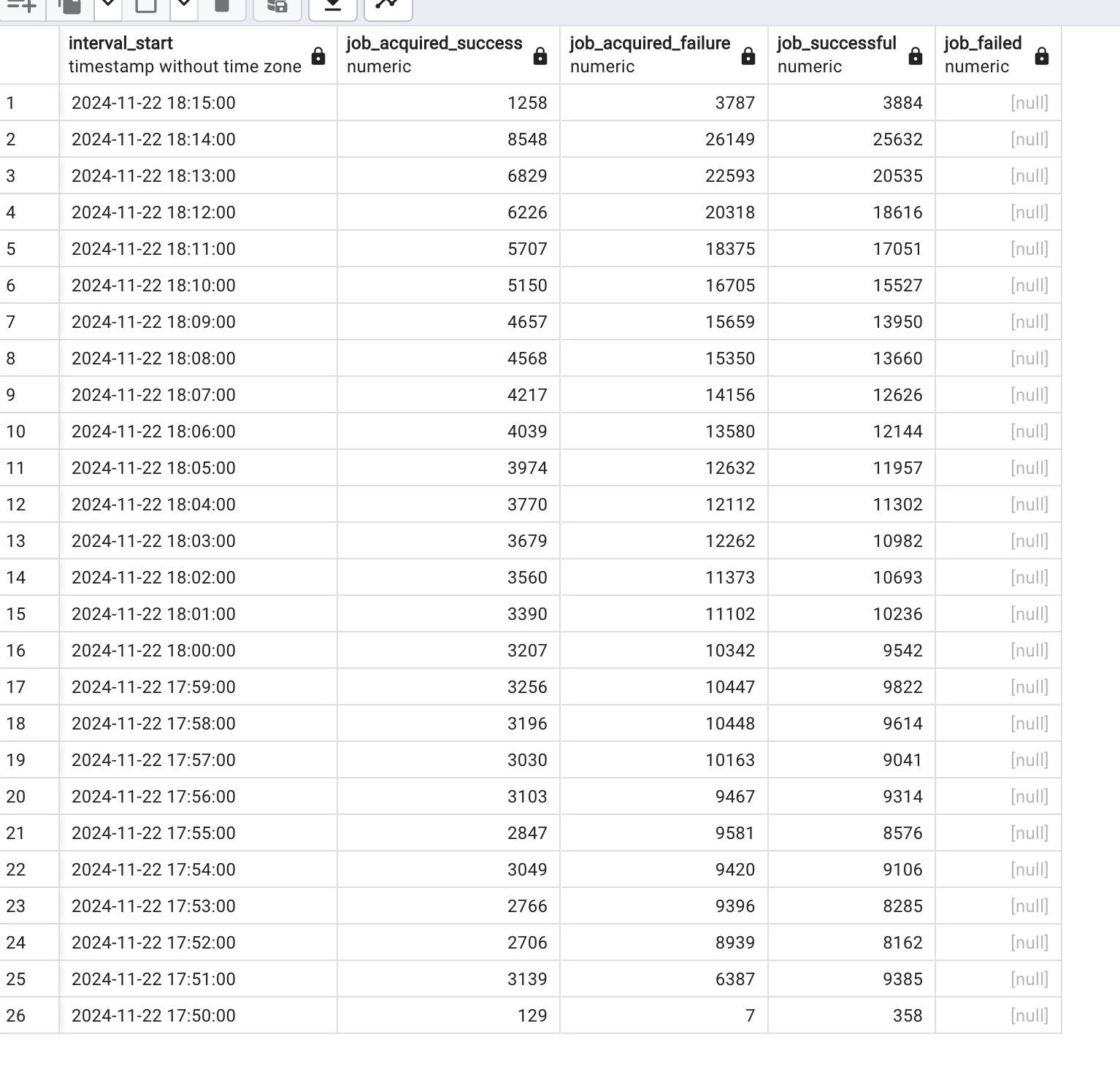
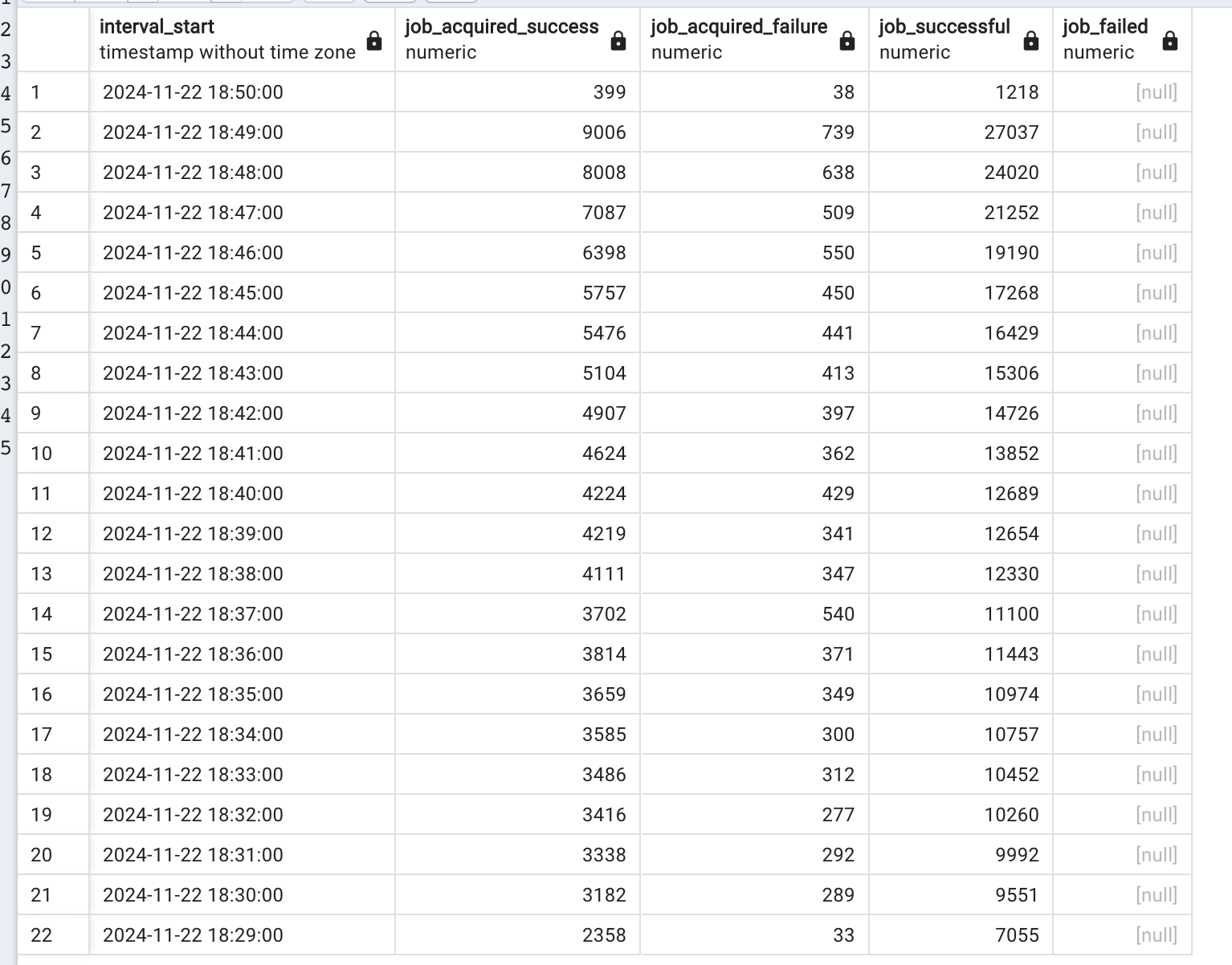
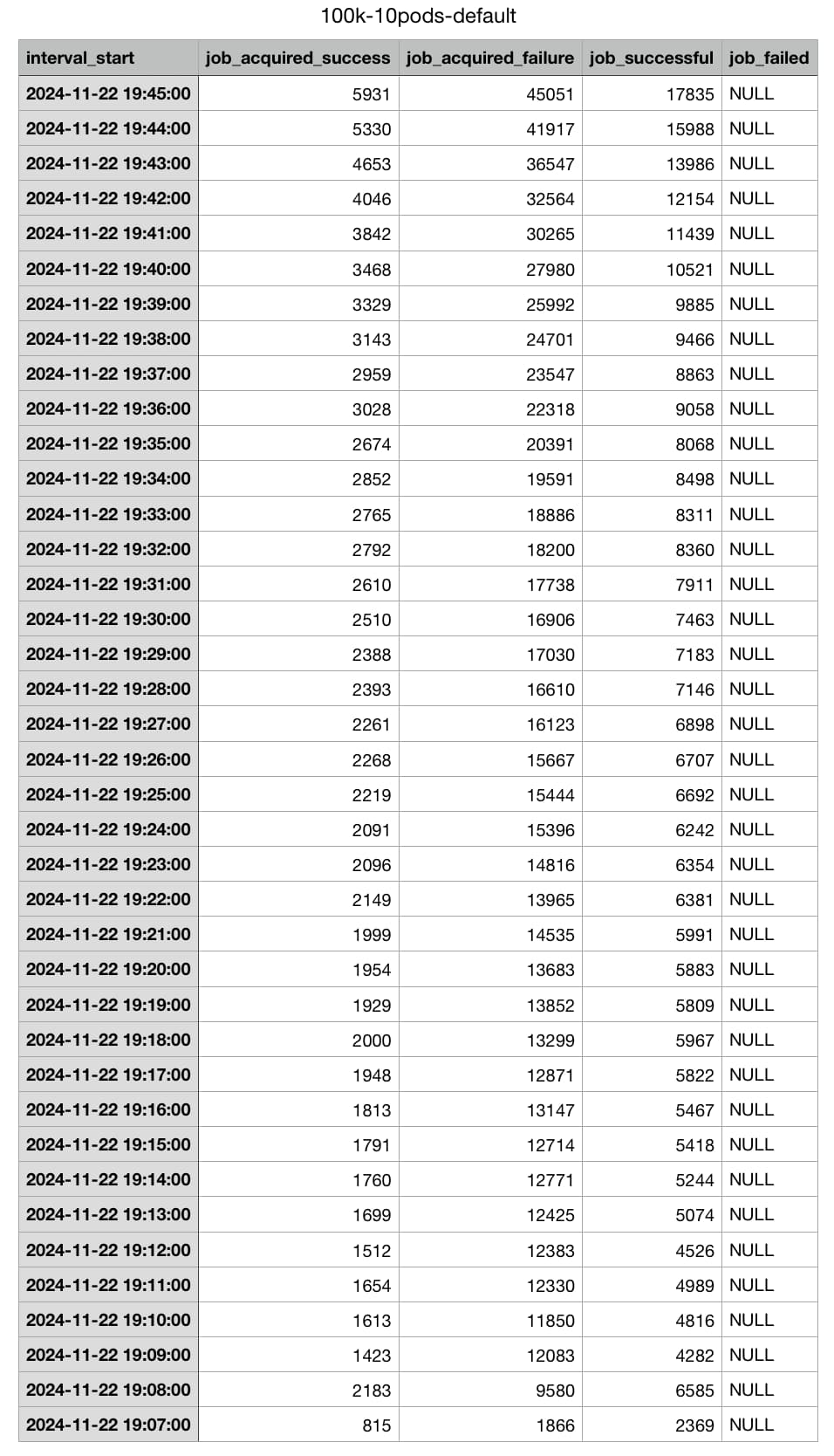
actually, our biggest process engine springboot project has this metrics on production:
Start Date
2024-01-01T00:00:00
End Date
2024-12-31T23:59:59
3,634,692,744 Flow Nodes Instances (FNI)
11,857,890 Process Instances (PI)
But it executes something like 30k root process instance per day. Now our newest challenge will be to execute 500k+ on the same day… its a very important day for out type of business.
if you have any tips & tricks to help on it, it will be of great help!
This week i’ll continue my tests, now ignoring the job execution reject hehe, and keep you informed here
also, have you changed the job executor to virtual threads on a springboot project? do you have this example for me?
on this environment ill be working on, we arent too afraid of putting more resources, as it will be a case of single day execution for the entire year, so im looking for ways to use as much resource as i can to speed it, but im worried about the increase in job acquisition failed as i start more containers…
maybe ill try to change the job acquisition query to do some pagination, giving a unique page identifier for each container, hoping that it will reduce the job lock cocurrency
I don’t have the example anymore, but I think I “patched” it in the engine for my experiment. In a Spring environment the org.operaton.bpm.engine.spring.components.jobexecutor.SpringJobExecutor should inject an instance of the org.springframework.core.task.TaskExecutor, that might be another point of entry.
It’s hard to make assumptions about performance, as it’s really important which kind of work is done on the threads. Slow HTTP calls just block the threads in the worker pool (virtual threads might be helpful, here), heavy calculations will impact the compute resources. Too many worker threads might produce too many locks on your database… Your best bet would be to set up a realistic performance test and run some experiments with different configuration there.
If you realize that the load is too high and minimal delay in execution is not critical you could externalise some of the load with External Tasks, so the node your engine is running on can use its resources for managing processes, while the worker nodes to the heavy lifting – also external tasks are not put into the job executors table, reducing the locks on that one.
Adding: If you use a recent Spring Boot version and Java 21 and you configure Spring to use Virtual Threads like this, the modified TaskExecutor should be injected as described above. I would file this under “experimental”, though, and you should only see a better througput if your Java Delegates are I/O heavy
Just to bring some updates on this subject…
i ve implemented a AcquireJobsCommandFactory which takes a unique index for each container/pod and use it to calculate an offset on the job acquisition query, in hope that it will reduce the concurrency over the same jobs, as each container will get a unique page in the query (and only a few jobs will move betweeen these pages between each acquisition).
I tested already with starting 100k process instances stoped in an async continuation and 2 more sequential async jobs, with job executor disabled, and the enabled it and restarted the containers.
From what I understand, job execution is tied to database transaction boundaries, making the database the ultimate bottleneck. But couldn’t the jobs be scheduled to a dedicated job queue (like Kafka)? Just curious if that approach could work. Implementing a manual partitioning algorithm feels to be the wrong approach because many other systems have already solved this kind of issue.
Yes, i think the best approach would be to just produce the jobs to a kafka topic and let the consumers do their work, but then we’ll have to rewrite a bunch of code for the failed jobs to be retried and other behaviors.
In this topic here, im just trying to boost it in the simplest way possible to have gains but dont have to worry about breaking any common behavior on my near future scenario, as these jobs are alrerady been creating months ago and waiting for the date on the database.
But for the future of operaton we can think about dispatch these jobs to an event stream, sure.
another thing we should look into is to use some document database for the variables, as some process with many variables will consume a lot of iops on relational databases using the default schema
could be easily optimized using postgres, but all the other supported databases are a problem because they’re basically unmaintained with our fork right now
In the default implementation, the more you try to scale it horizontal, the more concurrency youll have and thus job acquisition failed.
The same quantity of jobs that took 26 minutes to execute on 5 containers, now wth 10 containers took 39 minutes
It’s not that easy. Jobs in the Job Executor Table cannot be represented as a stream, easily, as they might have different priorities, or might be jobs created by timers, which only become relevant at a certain point in time.
Additionally, we should not forget that a secure, redundant Kafka broker is not that easy to host and maintain. If we add additional required infrastructure, then we might find ourselves with an engine that is harder to set up and maintain (and might suddenly need Helm charts and a K8S cluster )
I agree, that the locking mechanism on the job executor table has a lot of room for optimization
Kafka was just an example. I bet there are other solutions out there that better fit the embedded use case. I think the most challenging part is to support that many database systems. Looking at Supabase I’m always very surprised what they can achieve with Postgres.
and most of these points you said about a harder setup and requirements on infrastructure that made me stay with this version instead of move to a newer one. We have more than 100 different springboot projects acting on their own today, each one with business process from a different domain and on the right squad/team. The idea of having a single cluster for all my domain teams use isnt a reality for me, and to have such complex infrastructure to each one of them would be a massive over enginering too and be a lot harder to minitor and etc.
on our old projects we started using mysql but today most of the projects use postgresql for camunda and mongodb for business data, so we aim to have only ids and other metadata as process variable as we had too much problems scaling databases just because we hade large bytearray tables for the variables
actually i only implement a new AcquireJobsCmd and set a AcquireJobsCommandFactory on the default job executor.
Did you manage to override these mybatis query? if you have any example i could work on these tests
I then sent 1000 message events to the camunda_lead.
Processing with the unchanged engine and 10 nodes: 40 seconds
Processing with the unchanged engine and 5 nodes: 35 seconds
Processing with the adapted myBatis Query and 10 nodes: 22 seconds
This is not representative, of course, but I think it is an interesting experiment.
@javahippie Very nice idea how a little change might make a big improvement here. This could be also implemented in a way that it is only used on supported systems.
However I understand that @jradesenv needs a solution for a running production instance soon and cannot wait for these improvements to land in Operaton. Which Version of C7 do you have deployed there btw?